
Recently, a group of Chinese researchers from places like Carnegie Mellon University (CMU) came up with a fresh idea called “Critique Fine-Tuning” (CFT). This method trains AI using just 50,000 examples and still beats older techniques that need over 2 million examples in most tests.
Large Language Models (LLMs); the smart AI systems that help solve real-world problems; often rely on a technique called Supervised Fine-Tuning (SFT) to get better.
In SFT, the AI learns by copying high-quality answers, either written by people or created by other programs. This helps the AI follow instructions well. To make these training examples, researchers use tools like Self-Instruct and Evol-Instruct.
But there’s a catch. As you give SFT more and better examples, it doesn’t always improve much. Sometimes, if the AI is already good, adding SFT can even make it worse!
Three Chinese researchers from Carnegie Mellon University (CMU), the University of Waterloo, and other schools wrote a paper introducing a smarter way to train AI: Critique Fine-Tuning (CFT). Instead of just copying answers like the old method, CFT teaches the AI to think critically about them. This makes the AI learn better and deeper from its examples.

CFT moves away from simply copying and focuses on learning through critique—similar to how humans learn. Think about top students: they don’t just memorize answers; they study them, spot mistakes, and figure out how to make them better.
In CFT, the training examples include wrong answers along with explanations (critiques) about what’s wrong. The AI learns from these critiques, so it can spot errors, suggest fixes, and check if answers are right. This helps the AI get better at reasoning and handling tricky problems.
Let’s look at this problem:
You have a right triangle with sides of 3 units and 4 units. Build a square with it. What’s the area of pentagon ABCDE (in square units)?


Here’s a quick look at how their training examples differ:
The paper constructs a training dataset of 50K Q&A pairs with critiques, derived from WebInstruct. These critiques are generated by advanced models like GPT-4o. The above problem is one example. Most questions in the dataset focus on mathematics (65%) but also cover physics, chemistry, business, and other subjects.
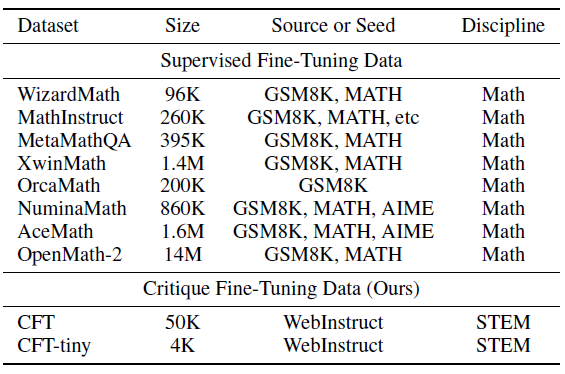
The researchers trained 7B-parameter instruction-untuned LLMs (such as DeepSeekMath-base, Qwen2.5, and Qwen2.5-Math) on the CFT dataset.
The training objective is straightforward: concatenate a problem x and an incorrect response y as input, then optimize model parameters to generate a critique c. In essence, the model learns critical thinking skills.
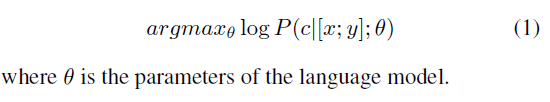
The researchers evaluated how LLMs performed on math-related benchmarks after instruction fine-tuning and critique fine-tuning. Results showed that CFT-trained models consistently outperformed the best SFT-trained models.
Compared to SFT, CFT improved accuracy by 4-10 percentage points on average. Additionally, CFT training was more efficient, requiring less data and converging faster, making it a promising method for developing mathematical reasoning models.
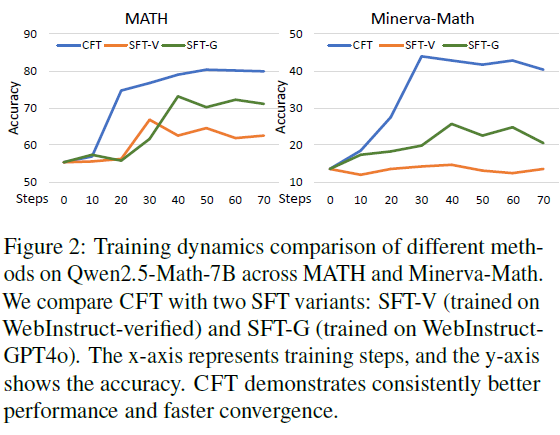
The following chart compares the training dynamics of different methods, including CFT and two SFT variants, using Qwen2.5-Math-7B on MATH and Minerva-Math. The x-axis represents training steps, while the y-axis shows accuracy.
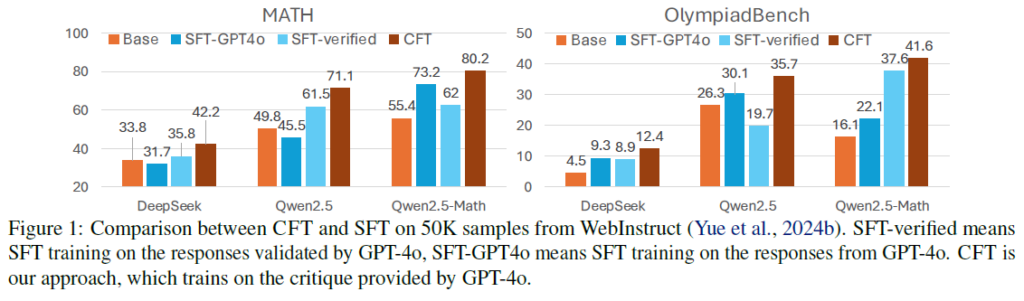
Even when trained on the same 50K samples, models using CFT showed greater performance improvements compared to SFT-trained models.
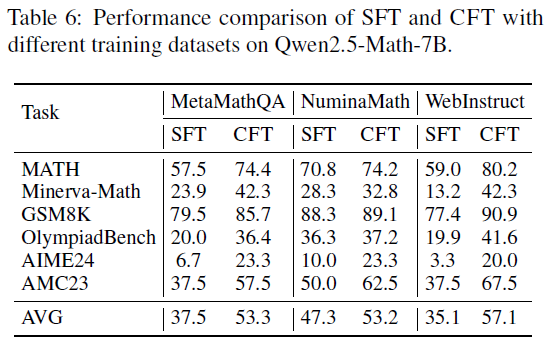
The researchers compared the fine-tuned Qwen2.5-Math-7B-CFT with well-known models such as Llama, GPT series, and other reasoning-specialized models like DeepSeek, Mathstral, and Numina. The results are shown below:
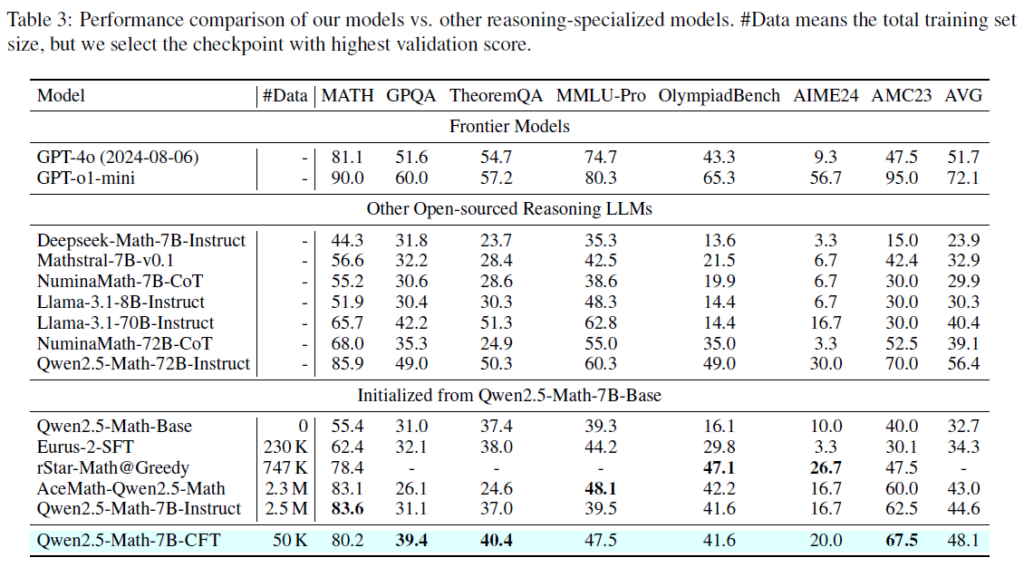
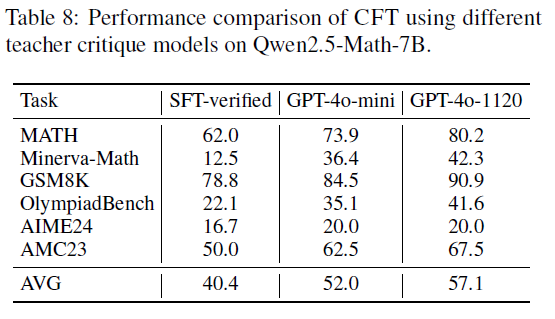
CFT’s key advantage is its significant boost to reasoning ability and efficient data utilization. By teaching models to critique, CFT functions as a single-step reinforcement learning approach.
Compared to self-correction and reward modeling, CFT aims to improve problem comprehension through critique-based learning rather than direct reward estimation or self-correction. This makes it more adaptable and flexible in reasoning tasks.
Crucially, CFT’s data construction and training process are simple and cost-effective, making it highly practical for real-world applications. Future research may focus on improving critique data quality and exploring self-critique mechanisms.
Potential directions include: